Research
I am currently working on topics related to music source separation using synthesis, analysis-by-synthesis, deep learning for audio generation and differentiable digital signal processing. Broader research interests include self-supervised learning, music information retrieval, timbre, optimal transport and generative models.
Publications
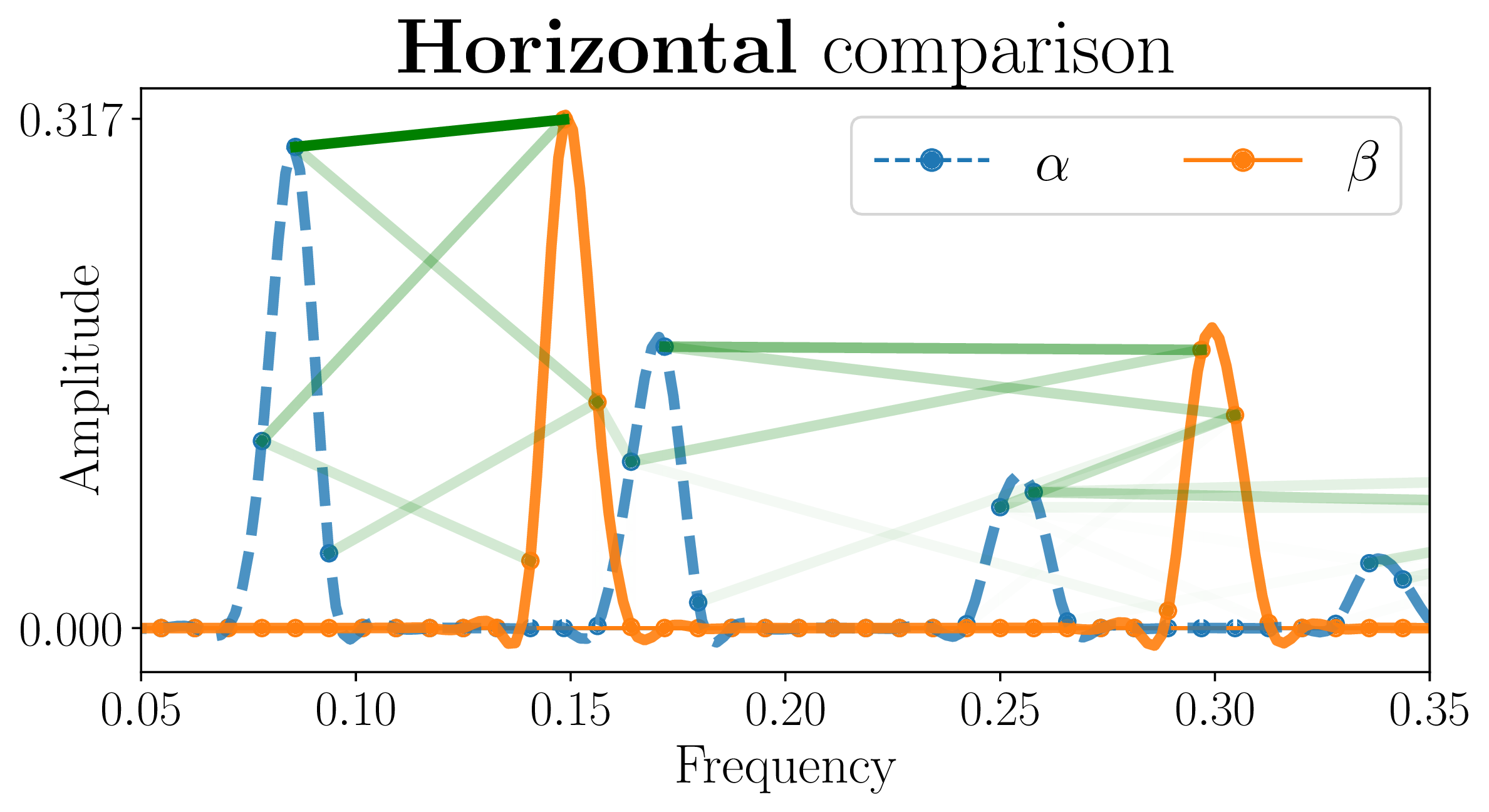
Unsupervised Harmonic Parameter Estimation Using Differentiable DSP and Spectral Optimal Transport
Bernardo Torres, Geoffroy Peeters and Gaël Richard
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024).
ABS
PDF (arXiv)
code
poster
In neural audio signal processing, pitch conditioning has been used to enhance the performance of synthesizers. However, jointly training pitch estimators and synthesizers is a challenge when using standard audio-to-audio reconstruction loss, leading to reliance on external pitch trackers. To address this issue, we propose using a spectral loss function inspired by optimal transportation theory that minimizes the displacement of spectral energy. We validate this approach through an unsupervised autoencoding task that fits a harmonic template to harmonic signals. We jointly estimate the fundamental frequency and amplitudes of harmonics using a lightweight encoder and reconstruct the signals using a differentiable harmonic synthesizer. The proposed approach offers a promising direction for improving unsupervised parameter estimation in neural audio applications.
A Fully Differentiable Model for Unsupervised Singing Voice Separation
Gaël Richard, Pierre Chouteau, and Bernardo Torres
In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2024).
ABS
PDF (hal)
A novel model was recently proposed by Schulze-Forster et al. in [1] for unsupervised music source separation. This model allows to tackle some of the major shortcomings of existing source separation frameworks. Specifically, it eliminates the need for isolated sources during training, performs efficiently with limited data, and can handle homogeneous sources (such as singing voice). But, this model relies on an external multipitch estimator and incorporates an Ad hoc voice assignment procedure. In this paper, we propose to extend this framework and to build a fully differentiable model by integrating a multipitch estimator and a novel differentiable assignment module within the core model. We show the merits of our approach through a set of experiments, and we highlight in particular its potential for processing diverse and unseen data.
Singer Identity Representation Learning using Self-Supervised Techniques
Bernardo Torres, Stefan Lattner and Gaël Richard
In International Society for Music Information Retrieval Conference (ISMIR 2023).
ABS
PDF (hal)
code
blog
poster
Significant strides have been made in creating voice
identity representations using speech data. However, the
same level of progress has not been achieved for singing
voices. To bridge this gap, we suggest a framework for
training singer identity encoders to extract representations
suitable for various singing-related tasks, such as singing
voice similarity and synthesis. We explore different selfsupervised learning techniques on a large collection of isolated vocal tracks and apply data augmentations during
training to ensure that the representations are invariant to
pitch and content variations. We evaluate the quality of
the resulting representations on singer similarity and identification tasks across multiple datasets, with a particular
emphasis on out-of-domain generalization. Our proposed
framework produces high-quality embeddings that outperform both speaker verification and wav2vec 2.0 pre-trained
baselines on singing voice while operating at 44.1 kHz. We
release our code and trained models to facilitate further research on singing voice and related areas.
Theses
2022
Singer identity conversion using self-supervised learning and differentiable source-filter models
Bernardo Torres
Master’s (M2) thesis for program Mathematiques, Vision, Apprentissage (MVA). Research performed while interning at Sony CSL Paris..
ABS
The human voice is a musical instrument highly limited by the physiology of the singer, making it
difficult for a singer to move out of the limitations of one’s voice. Compared to the most basic
synthesizers, existing systems designed for voice synthesis or transformation are still
rudimentary in terms of giving the user control of the timbral aspects of the sound. It is even
more so for perceptually-motivated synthesis, in which the user uses an intuitive control to
perform sound transformations (e.g. pitch and identity).
This work explores the domain of voice transformation, using the singer’s identity as the primary
control, a process known as Singing Voice Conversion (SVC). We focus on
answering two main questions: 1) how to extract the vocal identity of a singer, and 2) how can we control
it during synthesis?
We resort to recent developments in Deep Learning for obtaining (or learning) answers to
these questions using data-driven solutions. Furthermore, we design a voice modification
system that works on zero-shot conditions: it must generalize well outside the data used to train
it so anyone can use it with their voice.
For the first part, we explore Self-supervised learning (SSL) to obtain representations that
uniquely identify a singer based on an excerpt of his voice. SSL leverages significant amounts
of unlabeled data by solving a pretext (unsupervised) task without using labelled data, and the
learned representations can be transferred to other tasks. This work compares contrastive and
non-contrastive approaches and different neural network architectures. Metrics borrowed from
Singer Identification and Verification literature are used to evaluate the trained models and
compare them to baselines. A qualitative evaluation is also performed to assess the quality of
the learned identity representations.
In the second part, we explore audio synthesis architectures and modify them to inject the
identity information extracted in the first part. Changing only the injected identity information can
change the voice’s identity while keeping the linguistic information intact. We focus on a recent
trend in the domain of neural audio synthesis that attempts to join classical signal processing
techniques with the data-driven workflow of deep neural networks grouped under the name of
differentiable signal models. This work adapts a differentiable model based on the source-filter
model of speech production for the injection of identity information.